The eight ranking criteria
On this page
Algolia’s eight ranking criteria help define what’s both textually and business relevant.
Typo
Algolia is typo-tolerant. The Typo criterion in the ranking formula ensures the following ranking of search results for queries:
- Queries without typos (exact matches)
- Queries with one typo
- Queries with two typos
Typo vs Exact vs Words
Algolia’s Exact, Words, and Typo ranking criteria are all used to determine how well a record matches a query. However, they differ in the following ways:
| Criterion | Behavior | Helpful when |
|---|---|---|
| Typo | Returns results for queries that match all words in a record including those that contain a few typos. However, exact matches of the query terms rank higher | Some small user errors are likely |
| Exact | Returns results for queries that match all words in a record. The more closely the query sequence matches a record, the higher it will rank | Users are likely to type the query correctly, such as the name of a well-known product or company |
| Words | Returns results for queries that match some words in a record. | Misinterpretation of user input is more common such as in a voice-to-text search |
Geo (if applicable)
If you’re using the geo-search feature, results are ranked by distance, from the closest to the farthest.
The aroundPrecision parameter sets the precision of this ranking.
Words (if applicable)
This criterion only applies if you’re using the optionalWords setting.
By default, Algolia only matches results that contain all the query’s words. With optionalWords, you can declare some words as optional. The Words criterion ranks them by the number of matching words typed by the user (not the number of times the word appears in the record).
For example, if the user typed two words, the maximum score for this criterion is 2 - even if a record contains this word 10 times.
Filters
If a query uses filters or optional filters, this criterion ranks records according to the number of matching filters so that records that don’t match a filter score 0 and records that match two filters score 2.
You can adjust the scoring with:
- Filter scoring, you can assign different scores to each filter.
- Using sumOrFiltersScores to accumulate the scores of disjunctive (OR) matches to create a total score.
The Filters criterion can be helpful when defining relevance—for example, when promoting results.
Proximity
For a query with two or more words, Proximity calculates how near those words are to each other in the matching record. This criterion prioritizes records that have words closer to each other.
For example, consider two records with an actor_name attribute: George Clooney and George Timothy Clooney. If a user searches for “george clooney”, George Clooney has a better proximity distance (the two query words are 1 word apart) compared to George Timothy Clooney (the two query words are 2 words apart).
Attribute
This criterion only considers searchableAttributes: attributes at the top of the searchableAttributes list rank higher than lower ones.
The order of matches within the attribute itself is also important. By default, records with matched words closer to the beginning of a given attribute rank higher.
Exact
Records with words that exactly match query terms will rank higher. The more matching words in a record’s attribute, the higher that record’s rank. By default:
- An exact match is when a complete word in a query, without typos, matches a word in an attribute. Single-word queries are only exact if they match a single-word attribute.
- An inexact match has typos or only matches a prefix.
Additionally, synonym matching and plural/singular matching are considered exact. Thus, a word is considered an exact match if its synonym exactly matches a query.
You can change the settings for the Exact criterion.
Custom
This criterion takes into account your custom ranking attributes.
With multiple custom ranking attributes, the behavior is the same as other criteria: a criterion is only used if there is a tie between all the previous criteria.
For example, in the following custom ranking:
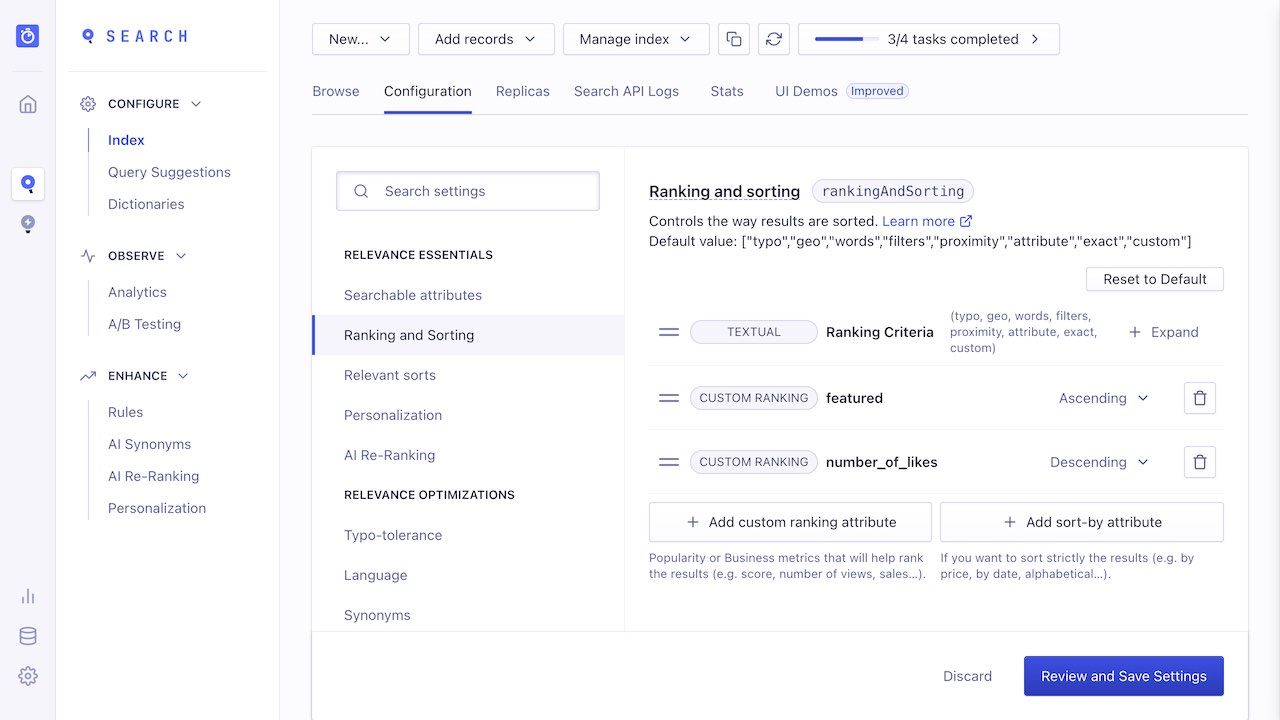
- Featured records (
featured) rank records set totruehigher than those set tofalse. - The number of likes (
number_of_likes) rank records based on this number: from the most to the least liked.
Attribute and proximity combinations
When Proximity appears before Attribute in the ranking, the calculation of Attribute ranking is different than if Proximity appears after Attribute. This is called the best-matched attribute.
This ordering is a subtle distinction. You should keep the default ranking since Proximity usually leads to better identification of the best-matched attribute.
Best-matched attribute
To determine the best-matched attribute, Algolia uses two computation methods:
- Closest in proximity. Ranking is based on how close two or more query terms are to each other
- Best position. Considers words near the beginning of an attribute to be better than those towards the end.
Algolia’s default ranking formula puts Proximity before Attribute, which has a subtle but important effect on computing the best-matched attribute: attributes with matched terms closest to each other will rank highest.
If you put Proximity after Attribute or remove the Proximity criterion, the best-matched attributes are those whose matched terms are in the best position.
Example
For example, consider an index with two searchable attributes, profession and full-name, and the following two records:
1
2
3
4
5
6
7
8
9
10
11
12
[
{
"profession": "Singer and comedian",
"full-name": "Jerry Lewis",
"objectID": "3"
},
{
"profession": "Born a singer",
"full-name": "Jerry Singer",
"objectID": "1"
}
]
Consider the search query “Jerry Singer”. The default ranking formula order is Proximity before Attribute*. In this case, the record containing the two words “jerry” and “singer” in closest proximity ranks higher (regardless of attribute order). For the two example records:
objectID1 has the query words side-by-side in the full-name attributeobjectID3 has the query words in different attributes.
Because the former has a better Proximity, it’s ranked first.
However, if you put Proximity after Attribute, the ranking is based on the best position of the matched terms in the searchable attributes (profession and full-name). Consequently, with the query “jerry singer”, the term “singer” appears in profession before full-name.
