A recommender system is, in layperson’s terms, software that filters down users’ choices and provides them with the most suitable suggestions based on their requirements or preferences.
The first recommender system was created in the 1970s, in the research community at Duke University; it was then developed by Xerox Palo Alto Research Center. When the Internet came into existence in the 1990s, recommender systems were immediately adopted as the way to help people select the most suitable products from a plethora of available options.
Since then, recommender systems have become more and more popular, and they now play a critical role for big Internet companies such as Facebook, Amazon, Netflix, Google, YouTube, and Tripadvisor, venturing into the realms of social networking, entertainment, ecommerce, tourism, matchmaking, and more.
In this blog series, we’re going to deconstruct the anatomy of recommendation engines, exploring what goes into building a performant one so that you’re better equipped when deciding how to integrate this functionality in your applications.
The four guiding principles for personalized recommender systems
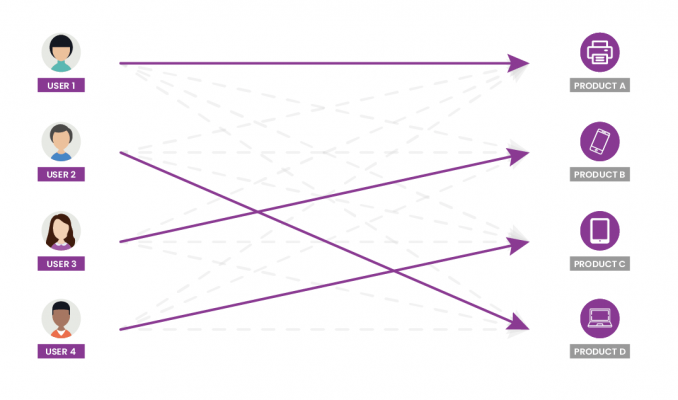
First, we need to make a distinction between non-personalized and personalizedrecommendation systems. With non-personalized recommendations, all users receive the same recommendations. Examples of non-personalized recommendations are popular movies, recent hit songs, and best-rated restaurants in a given location.
The most obvious operational goal of using a personalized recommender system is to recommend items that are relevant to the user, as people are more likely to buy items they find attractive.
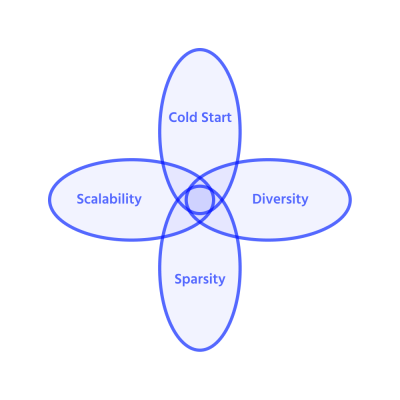
Recommenders need to achieve four secondary goals:
A. Cold start When insufficient information or metadata is available, a recommendation engine does not perform optimally. There are two (extreme) cold-start issues: when there’s no data about a user, which is divided into a lack of previous knowledge about the visitor and not enough information from the current session; and when there isn’t enough feedback or ratings from users. For example, let’s say a first-time visitor searches for a new smartphone on an ecommerce site. Within a week, he purchases one and is no longer interested in browsing phones. What should the recommendation engine display now?
B. Overcome data sparsity Data sparsity stems from the fact that users on an ecommerce website tend to interact with (add an item to the cart, purchase, or review) a limited number of items. Most recommendation engines group ratings of similar users; however, the reported user-item matrix has up to 99% empty or unknown ratings because of a lack of incentives for the user to rate items or enough knowledge about an item to rate it. As a result, users who provide no feedback or ratings receive irrelevant recommendations.
C. Scalability Scalability problems have significantly increased with the rapid growth of the ecommerce industry: modern recommendation engines are required to generate real-time results for large-scale applications. In other words, the performance of the recommendation model is measured in terms of throughput (number of inferences per second) and latency (time for each inference).
D. Diversity and novelty The most accurate results that recommendation engines can obtain are based on user or object similarity. This, however, exposes the user to a narrower selection of items — popular ones — while highly related niche items may be overlooked. The diversity of recommendations allows users to discover items that they would not readily find themselves.
Building a scalable architecture for a recommender
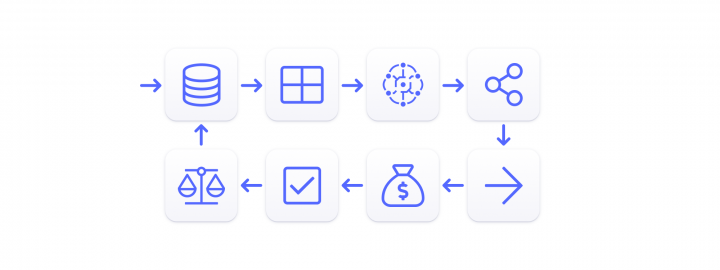
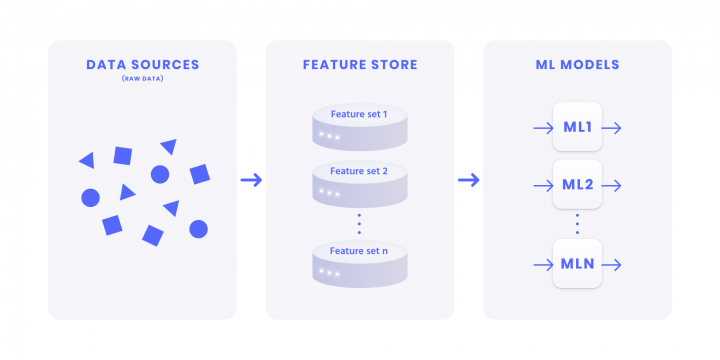
1. Data Sources 2. Feature Store 3. Machine Learning Models 4. Predictions 5. Actions 6. Results 7. Evaluation 8. AI Ethics
From an engineering point of view, to achieve the main goals for which it was built, the architecture of a recommender system must be scalable. There are 8 key components needed to accomplish this:
1. Data sources (DS)
Before diving into data sources, the first thing to understand is the implicit vs. explicit nature of ratings. Feedback in the form of ratings is explicit because users select numerical values in a specific evaluation system (e.g., a five-star rating model) that specifies their likes and dislikes of various items. In the implicit methodology of collecting feedback, a user’s browsing and purchase behavior, or their unary ratings (for example, whether they “like,” “read,” or “watch”) — in which a mechanism exists to express their affinity for an item — can be viewed as a rating signal. Today, many commercial systems allow the flexibility of providing recommendations to be based on both explicit and implicit feedback. That raises the question, “What are the best inputs for a recommendation engine?” At the very least, you’d want to include users, items, and explicit ratings (on a five-point scale):
USERS/ITEMS
U1
U2
U3
U4
U5
I1
1
❓
3
4
❓
I2
3
❓
❓
2
3
I3
2
5
3
❓
❓
I4
❓
4
1
❓
❓
I5
5
❓
2
❓
5
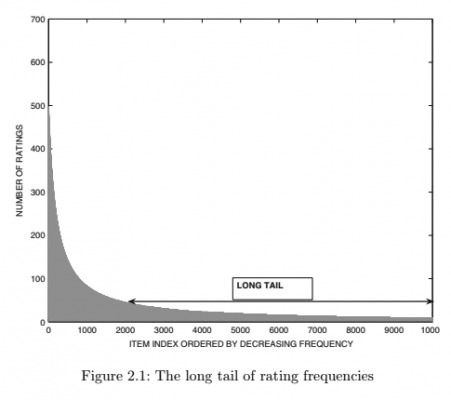
While this table has a few missing ratings (indicated by question marks), in reality, less than 1% of the items are rated frequently, and those can be referred to as popular items. The vast majority are rated rarely, which results in a highly skewed distribution of the underlying ratings — effectively, we’re dealing with a long-tail property of ratings.
There are two main sources of data that one can take into consideration for a recommender system:
Your go-to CMS (such as Shopify, Magento, or WooCommerce) for the product catalog (items) and user metadata (e.g., age and gender)
Google Analytics (or any third-party analytics platform) for interactions such as page views, time on site, and conversions
The aggregated data set could look something like this:
One of the most important and time-consuming aspects of building machine learning (ML) models is data preparation, and, specifically, feature extraction (or engineering). We all know it: 80% of the data scientist’s job is data preparation.
The feature extraction phase — in which the descriptions of various items are extracted — is highly application specific. Items may have multiple fields describing their various aspects. For example, an ecommerce business selling books might have an Item, Title, Description, Author, and Price field.
Item
Title
Description
Author
Price
I1
Later
The son of a struggling single mother, Jamie Conklin just wants an ordinary childhood. But Jamie is no ordinary child.
Stephen King
$10.88
I2
We Begin at the End
It’s set in a small town, where everyone knows Star Radley’s business—her drug addiction, the way her kids are neglected—but few extend a helping hand, besides Walk, the local sheriff who has a history with Star.
Chris Whitaker
$14.84
I3
2034: A Novel of the Next World War
From two former military officers and award-winning authors, a chillingly authentic geopolitical thriller that imagines a naval clash between the US and China in the South China Sea in 2034–and the path from there to a nightmarish global conflagration.
Elliot Ackerman, Admiral James Stavridis USN
$17.84
…
Aside from information describing each item, some recommender systems might also need user attributes (e.g., demographics) in addition to the data about the users’ ratings (implicit or explicit).
User
Last seen
Gender
Age
Country
Pageviews
Add-to-Cart
Order Value
U1
10/01/2021
male
45
Canada
13
0
0
U2
28/02/2021
female
25
US
5
1
$129
U3
01/02/2021
female
39
France
9
1
$98
…
To address this tedious challenge in the ML life cycle, the concept of a feature store was introduced: an interface between feature engineering and model development, a centralized data warehouse of features for data science teams that solves two issues. It:
Stores large volumes of features in a centralized manner, allowing DS/ML engineers to reuse, experiment with, and productize ML models faster
Serves features at low latency and high throughput to other applications or databases
Not all recommender systems have a hard requirement of a feature store; however, when DS/ML engineers are working on multiple machine learning initiatives, manual feature engineering could cause redundancies. So first and foremost, a feature store provides a single point of truth for sharing all available features. When a data scientist starts a new project, they can go to this catalog and easily find the features they are looking for. But a feature store is not only a data layer; it is also a data transformation service enabling users to manipulate raw data and store it as features ready to be used by any machine learning model.
Read more on Feature Store and Engineering.
3. Models
The basic models for recommender systems work with two kinds of data: user-item interactions, such as ratings and buying behavior, and attribute information about users and items, such as textual profiles and relevant keywords.
Here are the basic recommender system models:
Content-based filtering In content-based recommender systems, content plays a primary role in the recommendation process. Item descriptions and attributes are leveraged in order to calculate item similarity. In this context, the user-ratings matrix above is replaced by an item-content matrix with items in the rows and item attributes in the columns.
Collaborative filtering Collaborative filtering models use the collaborative power of ratings provided by multiple users to make recommendations. The basic idea is that unspecified ratings can be computed because observed ratings are often highly correlated across various users and items.
For example, consider two users, Julia and John, who are friends and have very similar tastes. If their ratings, which both of them have specified, are very similar, then their similarity can be identified by the underlying algorithm. In such cases, it is very likely that the ratings in which only one of them has specified a value are also likely to be similar. This similarity can be used to make inferences about incompletely specified values.
There are two main types of collaborative filtering:
User based The main idea behind user-based collaborative filtering (UB-CF) is that people with similar characteristics share similar tastes. For example, if Julia is interested in recommending a movie to John, as long as they have both seen many movies together and rated them almost identically, it’s safe to assume that they would continue to like similar movies.
Item based As opposed to UB-CF, item-item collaborative filtering is based on the similarity between items calculated using the ratings users have given the items. Therefore, John’s ratings of similar science-fiction movies, such as Alien and Predator, can be used to predict his rating of Terminator.
There are scenarios in which different sources of input can be used. For example, collaborative filtering systems rely on community ratings, content-based methods rely on textual descriptions and the target user’s own ratings, and knowledge-based systems rely on interactions with the user in the context of a knowledge base. Similarly, demographic systems use demographic profiles of users to make recommendations.
It is noteworthy that these different systems have different strengths and weaknesses. Some recommender systems, such as knowledge-based ones, are more effective in cold-start settings in which a significant amount of data is not available.
Other recommender systems, such as collaborative methods, are more effective when large amounts of data are available. In many cases, when a wider variety of inputs is available, one has the flexibility to use different types of recommender systems for the same task. In such cases, many opportunities exist for hybridization: the various aspects of different types of systems are combined to achieve the best results.
Content-based filtering and collaborative filtering are often used together because they complement each other well. Content-based systems suffer from overspecialization — they tend to recommend items that are similar to other items the user has seen. Collaborative recommenders, on the other hand, cannot effectively give recommendations for new items. The two approaches are often combined in hybrid recommender systems, thereby obtaining the best of both worlds.
At this point you’re able to generate recommendations — but how and where would you use them? For an ecommerce business, the standard approach is to display a “Recommended for you” widget on the product detail page.
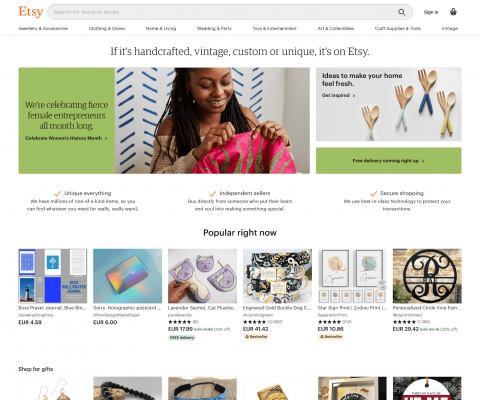
Etsy is a perfect example of an ecommerce platform that uses popular items to display recommendations. Here is its home page:
Notice the central positioning of the recommendations.
The idea behind displaying popular products first is that because so many shoppers have purchased them, other people are very likely to be interested in them, too.
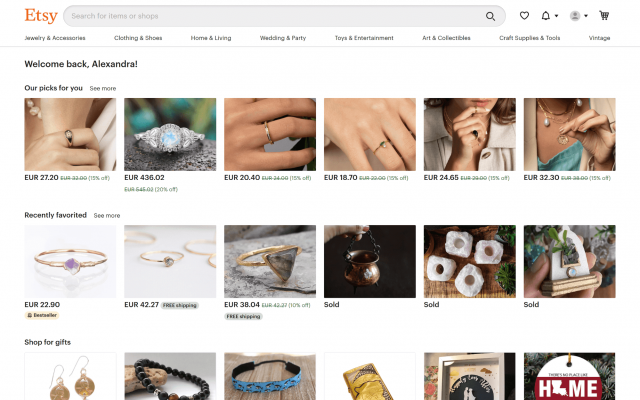
Although this method doesn’t really personalize the customer experience, showcasing popular items allows you to target first-time users who don’t have accounts. As a comparison, here’s what the Etsy homepage could look like after signing in:
The platform recorded all of the past product views and items added to favorites. Then it made automatic correlations with similar products from the same category or seller.
Recommender systems can also be used for cross-selling and upselling, which are aimed at helping people choose the best items for them while increasing the merchant’s revenue.
6. Business results and evaluating a recommender system
Given a set of recommendation algorithms, how well do they perform? How can you evaluate their relative effectiveness?
Developers are taking care of the technical aspects, but business leaders still have a major role: deciding the page on which to test product recommendations. It can be any page, as long as you can gather enough data. Preferably, send the test to only 20% of your traffic so you don’t break the recommendations for everyone if something goes wrong. If you want to safely test any of the above recommendation systems without interfering with live data, you can have your data or web development team do tests in its sandbox.
In either case, pay attention to your KPIs and how an individual technique affects them. If you haven’t done A/B testing, your click-through and conversion rates for every single item, and not just at a storewide level, are two safe choices you can start with.
Where do you go from here?
At this stage, you should not only be able to understand the benefits of using a recommender system but have an intuitive idea about the best approach for your application.
The primary purpose of AI-based ecommerce recommendation systems is to help you choose the right products to put in front of your users. Everything is backed by real data on products they’ve previously liked or shown interest in, so you’ll no longer have to guess what they might be looking for.
The future of custom product recommendation systems will allow you to target new user segments and be present everywhere: on social media, in mobile apps, in email, and of course, on your website. Simultaneously, you’ll be able to promote your entire range of merchandise, including new items, and even record data about user behavior as it occurs. So if a niche product’s popularity suddenly soars overnight, you won’t have to wait until the next morning to update your recommendations because all of this is done in real time.
This post is just the first in a series of blogs dedicated to the anatomy of a performant recommender system. Stay tuned for the next one, which will focus on data sources for recommender systems.
About the author
AI Product Manager | On a mission to help people succeed through the use of AI
Get your AI on!
The AI podcast where software developers and business leaders come together to share their experience in dealing with problems that can be solved through intelligent use of data.